يعود الفضل بالأداء الاستثنائي لنموذج الذكاء الاصطناعي Deepseek R1 إلى الجمع بين بنية مزيج من الخبراء (Mixture-of-Experts (MoE ومنهجية التدريب متعددة الخطوات التي تجمع بين التعلم المعزز (RL) والضبط الدقيق المُشرف عليه.
تُحسن بنية MoE الكفاءة من خلال تنشيط الجزء الضروري فقط من النموذج لكل رمز مُدخل، بينما يُمكّن نهج التدريب المعتمد على التعلم المعزز (RL) من تعلم مهارات الاستدلال المتقدمة بشكل مستقل.
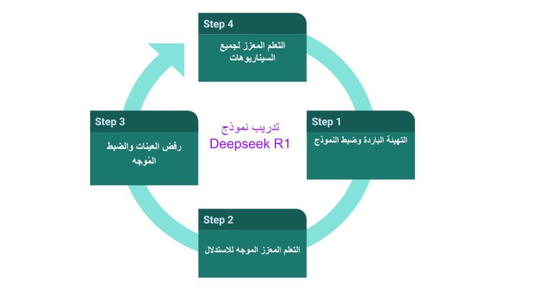
منهجية تدريب النموذج
تستخدم عملية التدريب أو ما بعد التدريب لنموذج ديبسيك R1 نهجاً متعدد المراحل يدمج التعلم المعزز (RL) مع الضبط الدقيق (Fine Tuning) المُشرف عليه. فيما يلي الخطوات:
1- التهيئة الباردة (Cold Start) وضبط النموذج:
تبدأ التهيئة الباردة (Cold Start) بجمع مجموعة صغيرة من الأمثلة عالية الجودة، وهي مسائل استدلال مؤلفة من عدة خطوات أو مايعرف بسلسلة الأفكار (CoT)، مثل تلك الموجودة في مسائل الرياضيات أو البرمجة، وتتضمن السؤال والإجابة التي تتألف من عدة خطوات. تُستخدم هذه المجموعة لضبط نموذج ديبسيك-V3-Base المُدرب مسبقًا، مما يعزز قدرته الأولية على إنتاج أفكار متسلسلة مقروءة ومنظمة.
2- التعلم المعزز الموجه للاستدلال (RL):
تشمل هذه الخطوة تدريب النموذج المضبوط من المرحلة السابقة لتحسين قدراته الاستدلالية. تتضمن قاعدة التدريب مجموعة متنوعة من مسائل الاستدلال المجمعة من مصادر مختلفة، مثل الكتب الدراسية، الإنترنت، ومنصات البرمجة.
يُنتج النموذج إجابات لهذه المسائل، ويقوم نظام المكافأة بتقييم كل إجابة بناءً على ثلاثة معايير:
- الدقة: صحة الإجابة النهائية.
- التنسيق: إمكانية قراءة عملية الاستدلال، باستخدام علامات <think> لعرض خطوات الاستدلال.
- اتساق اللغة: يُعاقب على المخرجات التي تخلط بين اللغات لضمان إنتاج النموذج خطوات استدلال مقروءة وواضحة.
تستخدم العملية خوازمية تحسين حديثة (GRPO)، التي تقيم إجابات مختلفة من النموذج للسؤال نفسه وتحسب أفضليتها بالنسبة إلى متوسط المكافأة لمجموعة الإجابات. يشجع هذا النهج النموذج على إنتاج استجابات أكثر ملاءمة دون الحاجة إلى تقديم أمثلة تدريب منقحة.
3- رفض العينات والضبط المُشرف عليه:
تُستخدم عملية رفض العينات لاختيار الإجابات عالية الجودة (مثل الصحيحة، المنسقة جيدًا، والخالية من خلط اللغات) من بين عدد كبير من المخرجات التي يُنتجها النموذج المدرب بالتعلم المعزز، والتي تُدمج بعد ذلك مع بيانات الضبط المُشرف عليها من مجالات أخرى (الكتابة، الإجابة على الأسئلة الواقعية، إلخ) لضبط النموذج بشكل أكبر.
4- التعلم المعزز لجميع السيناريوهات:
تُحسن مرحلة التعلم المعزز الثانية هذه سلوك النموذج من خلال الاستفادة من مجموعة متنوعة من المكافآت. يتضمن ذلك مكافآت موجهة للاستدلال لمهام ذات قواعد واضحة، مثل الرياضيات أو البرمجة، ومكافآت تفضيل البشر لتتوافق مع قيم مثل الفائدة وعدم الضرر. بالإضافة إلى ذلك، يُدرب النموذج على مجموعة متنوعة من الأسئلة لتحسين قابليته للتعميم.
تسمح هذه العملية متعددة المراحل لنموذج ديبسيك R1 بالاستفادة من قوة التعلم المُشرف عليه والتعلم المعزز، مما يؤدي إلى نموذج يتمتع بقدرات استدلال قوية، وإمكانية قراءة محسنة لمخرجاته، وتوافق أفضل مع تفضيلات البشر.








